
Czym są programy CAT
Jeśli zajmujecie się wyłącznie tłumaczeniami literackimi i kreatywnymi, mogliście nigdy nie używać żadnego specjalnego oprogramowania do tłumaczenia poza słownikami i edytorem tekstu, ale mogliście słyszeć o programach do „komputerowego wspomagania tłumaczeń” (Computer Assisted Translation, CAT). Stworzono je z myślą o tłumaczeniach technicznych a ich głównym założeniem jest idea, że „nigdy nie trzeba dwa razy tłumaczyć takiego samego zdania”, co ma mnóstwo sensu w świecie powtarzalnych tekstów komunikacji technicznej (np. instrukcji obsługi), ale czy takie oprogramowanie może się do czegoś przydać w tłumaczeniach literackich? Zaznaczam, że tekst w najmniejszym stopniu nie dotyczy tłumaczeń maszynowych (Machine Translation, MT). Zapraszam do lektury.
Zacznę od paru słów o sobie: teksty literackie zacząłem tłumaczyć w 2000 r., wciąż pracując nad (nieudanym) doktoratem z chemii, a robiłem to „przepisując” papierową książkę w edytorze tekstu. Po kilku kolejnych usprawnieniach ergonomicznych któraś kolejna książka była już tekstem w formie elektronicznej, a tłumaczenie wpisywałem w drugim oknie na ekranie. I gdzieś po drodze zacząłem wykonywać również tłumaczenia tekstów „technicznych” (chemia i medycyna), gdzie wymagane było używanie narzędzi CAT. A gdy w dostatecznym stopniu przyzwyczaiłem się do tego oprogramowania, zacząłem go używać również do tłumaczeń literackich, których mam za sobą prawie 40. I bardzo je sobie cenię.
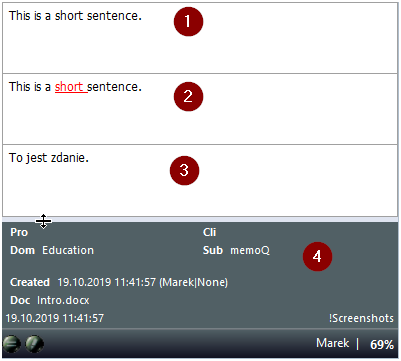
Jak działają programy typu CAT? Podstawowa zasada działania polega na tym, że tekst do tłumaczenia jest dzielony (segmentowany) na zdania, a gdy raz przetłumaczy się zdanie (segment), tekst źródłowy i tłumaczenie zapisywane są w bazie danych nazywanej pamięcią tłumaczeń (Translation Memory, TM), której można używać w kolejnych tłumaczeniach i przesyłać innym. Gdy w przyszłości napotka się identyczny segment, oprogramowanie wstawi istniejące tłumaczenie, dzięki czemu nie trzeba tracić czasu na coś, co wcześniej przetłumaczyliśmy – lub zrobił to ktoś inny, jeśli wraz z plikami do tłumaczenia dostaliśmy pamięć tłumaczeń – zapewniając tym samym spójność, co jest istotnym elementem komunikacji technicznej. W przypadku natrafienia na zdanie podobne do czegoś, co zostało już przetłumaczone (tzw. „dopasowanie rozmyte”), program również wyświetli wcześniejsze tłumaczenie podkreślając różnice między bieżącym segmentem źródłowym a tym z pamięci tłumaczeń, co znowu przyspiesza tłumaczenie i ułatwia zachowanie spójności.
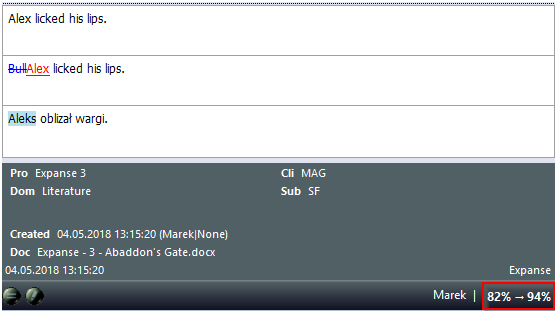
Podstawienie z pamięci tłumaczeń w programie memoQ: (1) bieżące zdanie do tłumaczenia, (2) podobne zdanie znalezione w pamięci tłumaczeń ze wskazaniem różnic między bieżącym tekstem i dopasowaniem z TM, (3) tłumaczenie segmentu znalezionego w TM, (4) informacje o podstawieniu: kto i kiedy je przetłumaczył/edytował, jak nazywał się dokument, z którego pochodzi, poziom podobieństwa (procentowy poziom dopasowania) itp.
Oczywiście identyczne tłumaczenie takich samych lub bardzo podobnych segmentów to niekoniecznie coś, czego chcemy w tłumaczeniach literackich, choć czasem bywa to potrzebne, a narzędzia CAT oferują dużo więcej, niż tylko pomoc w zachowaniu spójności i zdecydowanie pomagają mi pracować dużo wygodniej i wydajniej. Zobaczmy jak.
Korzyści
Tak naprawdę nigdy nie tłumaczyłem książek w Wordzie – używałem edytora tekstów pod Linuksem, ale zasada była taka sama: tekst źródłowy w oknie edytora, tłumaczenie w drugim oknie z prawej/lewej/powyżej/poniżej, dopilnować właściwej wielkości okien i pracujemy. Trzeba tylko co kilkadziesiąt linijek przełączyć okna, żeby przewinąć tekst źródłowy. W przypadku dłuższej przerwy trzeba też poświęcić chwilę na wyszukanie w tekście właściwego miejsca do tłumaczenia, co może potrwać dłużej, jeśli z dowolnego powodu trzeba było zamknąć okno edytora. Oczywiście takie wyszukiwanie jednorazowo nie trwa zbyt długo, ale nawet te chwile się dodają, a zdarzy się, że pominiemy jakieś zdanie.
Gdy zaczyna się tłumaczenie z programem CAT zwykle wymagane jest przygotowanie, ponieważ większość programów stosuje podejście „projektowe”: należy utworzyć projekt z wybraną nazwą, wybrać język źródłowy i docelowy oraz utworzyć nową/wybrać istniejącą pamięć tłumaczeń i bazę terminologii, a potem zaimportować plik(i) do tłumaczenia. Jednak w przypadku tłumaczeń literackich zajmujących średnio parę miesięcy trwające najwyżej kilka minut przygotowanie nie stanowi problemu – oczywiście wymagany jest tekst źródłowy w formie elektronicznej. Po utworzeniu projektu można przeprowadzić analizę – oprogramowanie poinformuje, ile segmentów/słów/znaków znajduje się w pliku źródłowym i czy są jakieś powtórzenia – identyczne segmenty występujące więcej niż raz. W przypadku tekstów literackich zwykle będą to krótkie elementy typu „Rozdział”, a w przypadku tłumaczeń z angielskiego również krótkie fragmenty dialogów „he/she said” i tym podobne. Przeprowadzenie analizy jest też świetnym sposobem na śledzenie postępów pracy: choć program wyświetla informacje o postępie tłumaczenia w czasie rzeczywistym, osobiście cenię sobie możliwość śledzenia postępów w czasie, więc zawsze wykonuję analizę na koniec dnia pracy, dzięki czemu mogę śledzić postępy. Jednak analiza nie jest bezwzględnie konieczna, w przeważającej większości wypadków liczba słów/znaków będzie taka sama, jak podana przez Worda.
Pora przejść do tłumaczenia zaimportowanego tekstu. W zależności od używanego oprogramowania, program będzie wyświetlał różne poziomy formatowania – niektóre narzędzia, takie jak SDL Trados Studio odtwarzają pełne formatowanie tekstów z Worda, włącznie z kolorem i rozmiarem czcionki, podczas gdy inne, jak memoQ, wyświetlają tylko podstawowe formatowanie (wytłuszczenie, kursywę i podkreślenie), stosując jednolitą czcionkę do całego tekstu. Osobiście wolę to podejście, bo dzięki niemu łatwiej skupić się na treści. Warto pamiętać też o wyłączeniu funkcji „auto-propagate”, która automatycznie wstawia zatwierdzone tłumaczenia do identycznych segmentów w tekście (np. fragmenty dialogów; w memoQ Translations > Translations settings > Auto-propagation > wyłączyć).
Przyjrzyjmy się teraz zasadniczym korzyściom oferowanym przez programy CAT
- Skupienie uwagi/ergonomia – niezależnie od czcionek, w przypadku większości programów CAT tekst źródłowy wyświetlany jest w segmentach: każde zdanie osobno, a tłumaczenie wpisuje się (w zależności od programu i/lub ustawień) na prawo od źródła lub poniżej. Ma to trzy zalety: pomaga skupić się na pojedynczym zdaniu (patrz uwaga w części o wadach) i sprawia, że znalezienie bieżącego tekstu do tłumaczenia jest bardzo łatwe – zwykle znajduje się na środku ekranu, w jakiś sposób wyróżniony. Trudno też jest pominąć jakąś część tekstu, bo program wyświetli ostrzeżenie w przypadku próby wyeksportowania tekstu z brakującymi segmentami.
- Formatowanie – mamy do czynienia z mniej lub bardziej „czystym” tekstem, z ilością formatowania widocznego na ekranie zależną od konkretnego programu i preferencji. Jeśli akapity tekstu źródłowego są sformatowane w jakiś skomplikowany sposób, w ogóle nie trzeba się tym martwić, bo program odtworzy to formatowanie przy eksporcie gotowego tłumaczenia. Można się skupić na tłumaczeniu pilnując tylko prostego formatowania w rodzaju wytłuszczenia lub wstawiając specjalne znaczniki w przypadku bardziej złożonego formatowania.
Oryginalne formatowanie jest przy tym zwykle wyświetlane w formie podglądu aktualizowanego na żywo w interfejsie programu, z tłumaczeniem wstawianym w miejsce gotowych segmentów źródłowych.
- Bazy terminologii – można używać bazy terminologii/glosariusza do przyspieszenia pisania i zapewnienia większej spójności. Potrzebne przetłumaczenie nazwy jakiegoś miejsca albo np. statku? Wystarczy dodać nazwę źródłową i jej tłumaczenie do bazy terminologii (zwykle przez proste zaznaczenie i użycie polecenia z interfejsu lub skrótu klawiszowego). Jeśli nazwa wystąpi w segmencie źródłowym zostanie podświetlona, a właściwe tłumaczenie będzie wyświetlone gdzieś w interfejsie użytkownika programu. Możesz wtedy szybko wstawić tłumaczenie przez dwukrotnie kliknięcie, użycie skrótu klawiszowego lub po prostu przez wpisanie paru pierwszych liter i skorzystanie z podpowiedzi pisania. W tekście występują długie i złożone nazwy miejsc, imiona czy nazwiska albo nazwy firm lub produktów? Wystarczy dodać je do bazy terminologii, by szybko wstawić. Tłumaczenie z angielskiego na polski, w którym jednak trzeba znać płeć postaci, by właściwie je odmieniać, a dana osoba występuje w tekście rzadko? Wystarczy wrzucić imię do bazy terminologii z zaznaczeniem płci: będzie można szybko wpisać imię i jednym spojrzeniem sprawdzić właściwą formę.

- Szybsze pisanie – wpisy bazy terminologii można wstawiać bardzo szybko, ale działa to też dla całych krótkich segmentów, a na dodatek niektóre programu, jak memoQ czy SDL Trados Studio mogą generować specjalne słownik „automatycznego pisania”, które sugerują słowa a nawet wielowyrazowe zwroty na podstawie zawartości segmentu źródłowego. Sprawdza się to najlepiej w przypadku większych pamięci tłumaczeń, choć dla języków fleksyjnych, takich jak polski, problemem może być mnogość form.

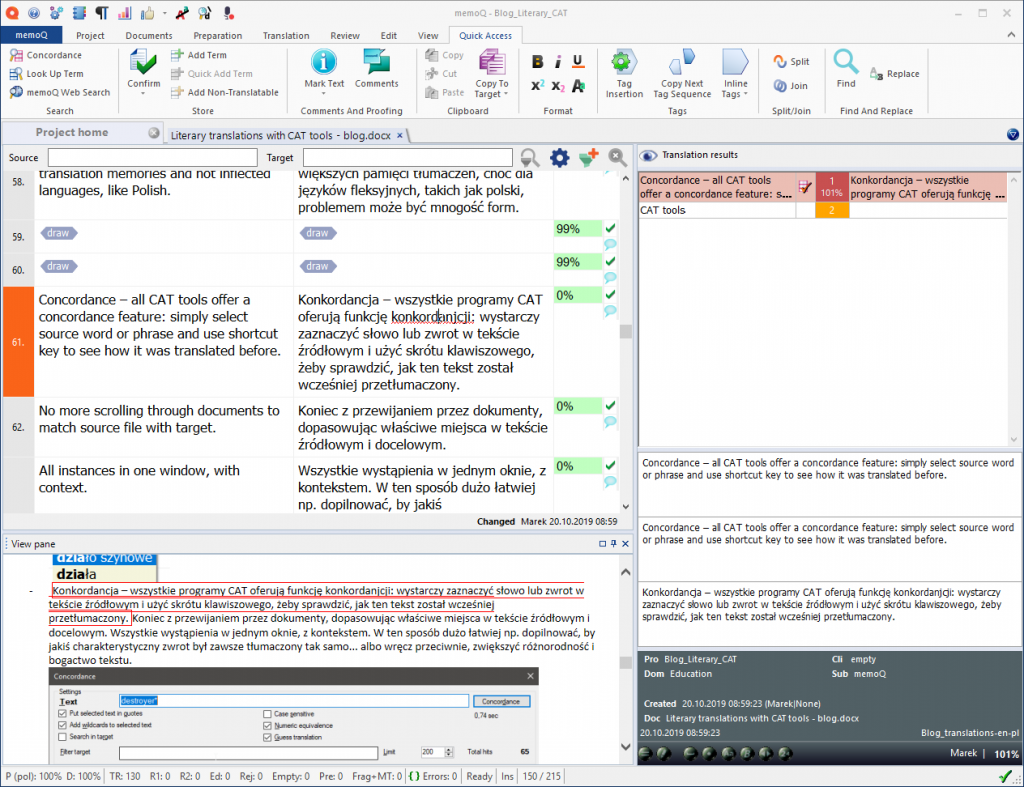
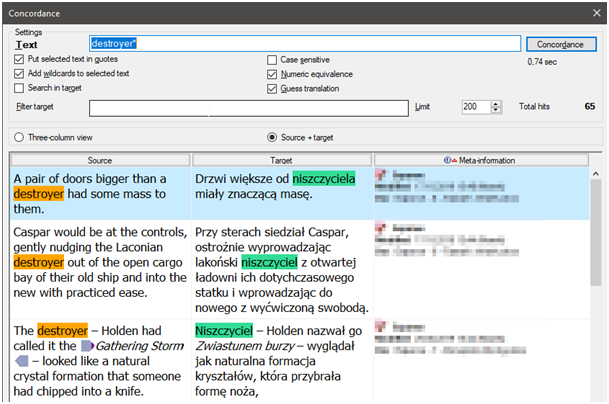
- Konkordancja – wszystkie programy CAT oferują funkcję konkordancji: wystarczy zaznaczyć słowo lub zwrot w tekście źródłowym i użyć skrótu klawiszowego, żeby sprawdzić, jak ten tekst został wcześniej przetłumaczony. Koniec z przewijaniem przez dokumenty, dopasowując właściwe miejsca w tekście źródłowym i docelowym. Wszystkie wystąpienia w jednym oknie, z kontekstem. W ten sposób dużo łatwiej np. dopilnować, by jakiś charakterystyczny zwrot był zawsze tłumaczony tak samo… albo wręcz przeciwnie, zwiększyć różnorodność i bogactwo tekstu.
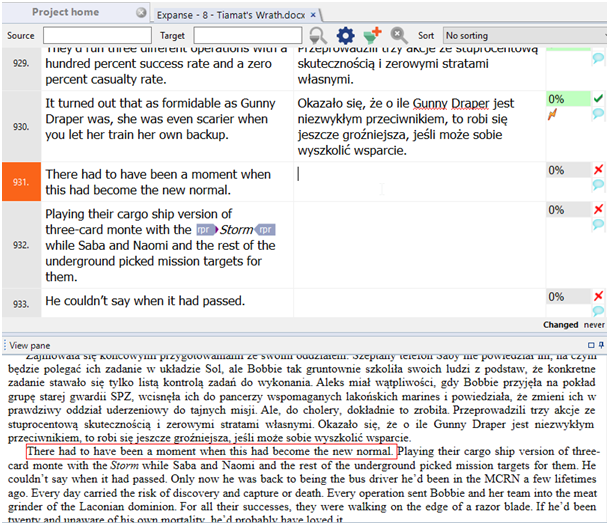
- Automatyczna konkordancja – może być jeszcze lepiej: krótkie, często występujące segmenty (np. „he said” w angielskich dialogach) oraz ich tłumaczenie mogą być wyświetlane automatycznie. I znowu, można tego użyć do zapewnienia spójności lub zwiększenia różnorodności, często pożądanej w tekstach literackich.
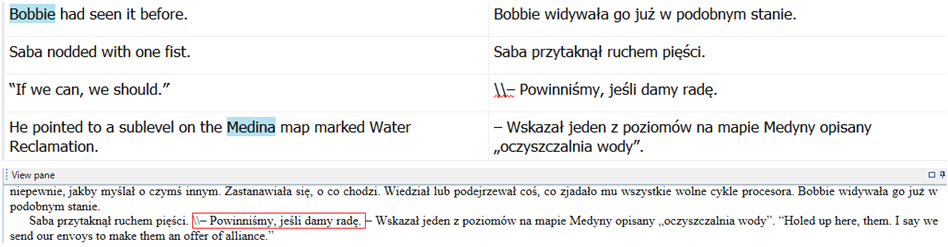
- Cytaty – czy autorowi zdarza się powtarzać jakieś fragmenty tekstu? Może ktoś przypomina sobie wcześniejszą wypowiedź? To dość częsty zabieg np. w kryminałach. Nie trzeba już szukać, jak wcześniej przetłumaczyliśmy ten tekst, program sam podpowie istniejące tłumaczenie. I nawet pokaże różnice, jeśli autor zmienił coś w cytacie (świadomie lub nie).
- Komentarze – czy korzystacie z komentarzy do tekstu, żeby zapisać sobie np. coś do sprawdzenia później? Żaden problem, wystarczy użyć funkcji komentarzy i przydzielić danej notatce jedną z kilku dostępnych kategorii (np. informacja, ostrzeżenie itp.). Później można przefiltrować tekst do szybkiego wyświetlenia tych z komentarzami, a nawet wyeksportować komentarze (wszystkie lub określoną kategorię) do dokumentu docelowego.
- Nic nie zginie – po zatwierdzeniu segmentu (Ctrl-Enter), jego status w edytorze tłumaczeń zmienia się na zatwierdzony, a oprócz tego zostaje zapisany w pamięci tłumaczeń (bazie danych). Niektóre programy równocześnie zapisują cały plik, w innych zapis całości odbywa się w zdefiniowanych odstępach czasowych. Nawet jeśli dojdzie do awarii systemu lub przerwy w zasilaniu, tłumaczenie jest bezpieczne – można zawsze je przywrócić z pamięci tłumaczeń. Zapewnia to dodatkowy poziom bezpieczeństwa / kopii zapasowej pracy.
- Śledzenie postępów / zwiększona produktywność – program CAT pokazuje postępy pracy w czasie rzeczywistym na podstawie liczby segmentów, słów lub znaków. Wspominałem już o funkcji analizy oraz informacji o postępach, ale praca z segmentami oferuje dodatkową zaletę: można je wykorzystać do zmodyfikowanej techniki Pomodoro, w której zamiast określonego czasu, skupiamy się na tłumaczeniu do ukończenia określonej liczby segmentów. W moim przypadku dla tłumaczeń literackich trzymam się 50 – zaczynając pracę ignoruję e-maile, powiadomienia i inne rozpraszacze do czasu przetłumaczenia 50 segmentów. Wtedy robię sobie przerwę (może to być Facebook, zaparzenie herbaty albo nastawienie prania) i siadam do kolejnej porcji. Liczba segmentów może być różna, w zależności od złożoności tekstu źródłowego, ale ta technika pozwoliła mi znacząco poprawić produktywność. Co więcej, niektóre programy (np. memoQ) mają możliwość automatycznego rejestrowania czasu pracy (Options > Miscellaneous > Editing time > Reord editing time when I am working; raporty generuje się przez wybranie Project home > Overview > Reports > Editing time), co może być przydatne dla osób zainteresowanych faktyczną wydajnością swojej pracy.\\Oczywiście do stosowania techniki Pomodoro nie trzeba używać programu CAT i można skupiać się na pracy np. na jedną stronę, ale dla mnie liczba segmentów świetnie się sprawdza.
- Filtrowanie na podstawie słów/zwrotów – pisałem już, że łatwo sprawdzić, jak coś zostało wcześniej przetłumaczone, ale co zrobić, gdy zmienimy zdanie i chcemy użyć innego tłumaczenia? Zawsze można użyć funkcji znajdowania i zamiany, ale w programach CAT mamy też do dyspozycji filtrowanie na podstawie tekstu źródłowego lub docelowego. Funkcja ta dostępna jest tylko w programach stosujących interfejs „tabelkowy”, jak na zamieszczonych tu zrzutach ekranowych, ale umożliwia wyświetlenie wszystkich wystąpień wyszukiwanej frazy i dostosowanie tłumaczenia w kontekście, w razie potrzeby z modyfikacją form gramatycznych reszty tekstu.
- Wbudowane/opcjonalne narzędzia wyszukiwania w Internecie – nie są dostępne we wszystkich programach, ale te lepsze oferują tę funkcję. Trzeba coś sprawdzić w Google/Bing lub użyć jakiegoś słownika online? Po skonfigurowaniu wbudowanej/opcjonalnej funkcji wyszukiwania w sieci, wystarczy zaznaczyć słowo lub zwrot i użyć skrótu klawiszowego, do wyszukania tego tekstu we wszystkich zdefiniowanych serwisach równocześnie (w memoQ: Options > Default resources > Web search).
- Automatyczne poprawianie dopasowań rozmytych – w tekstach literackich funkcja ta nie przydaje się często i niekoniecznie korzystam ze zmodyfikowanych w ten sposób tłumaczeń, ale czasami dopasowanie rozmyte (zdanie zapisane w TM podobne do bieżącego) może zostać automatycznie „poprawione” odpowiednio do bieżącego tekstu. I czasami można taki tekst zachować bez modyfikacji.
Dostępne są oczywiście także inne przydatne funkcje, takie jak możliwość wygenerowania dokumentu Worda z tabelą zawierającą tekst źródłowy i docelowy w sąsiednich komórkach do szybkiej weryfikacji w Wordzie, listy autokorekty, możliwość używania wcześniejszych tłumaczeń jednojęzycznych jako plików referencyjnych, funkcje kontroli jakości (technicznej, jak sprawdzanie poprawności liczb) i wiele innych.
Ograniczenia
To co, same zalety? Podobnie jak w przypadku każdego oprogramowania, są pewne ograniczenia.
- Tłumaczenie zdaniami – jak już wspominałem, w programach CAT pracuje się z segmentami, które przeważnie są zdaniami. Choć bardzo łatwo jest zmienić podział tekstu na akapitowy, traci się w ten sposób sporo zalet CATów. W tłumaczeniach literackich/kreatywnych konieczne jest uwzględnienie szerszego kontekstu, zwykle przynajmniej całego akapitu (zwracam uwagę, że kontekst jest istotny również w tłumaczeniach technicznych). Segmentacja zdaniowa ułatwia skupienie się na bieżącym zdaniu, choć równocześnie trochę utrudnia myślenie o całym akapicie, zwłaszcza osobom początkującym. Przy tym to wcale nie tak, że tekst poza bieżącym segmentem jest ukryty – wręcz przeciwnie, bieżący segment jest wyróżnionym elementem interfejsu, w którym wyraźnie widoczne są poprzednie i następne segmenty, to tylko kwestia właściwego podejścia. A jeśli wymagany jest jeszcze szerszy kontekst, wystarczy spojrzeć na podgląd, którego okno można ustawić tak, by obejmowało np. całą stronę.
Podczas pracy z tekstem literackim często wymagane jest odstępowanie od źródłowego podziału na zdania – połączenie dwóch lub większej liczby krótkich zdań (segmentów) źródłowych w jedno zdanie tłumaczenia lub podzielenie długich zdań na krótsze. W praktyce to bardzo proste: podzielenie długiego zdania na krótsze wymaga po prostu wpisania dwóch zdań w jednym segmencie (choć można i użyć funkcji podzielenia segmentu źródłowego). Przerobienie kilku krótkich zdań źródła w jedno zdanie tłumaczenia może polegać na połączeniu segmentów źródłowych w jeden (jedna „komórka” tabeli), albo po prostu tłumaczeniu fragmentów w odpowiednich segmentach z użyciem właściwej interpunkcji. W gotowym pliku tłumaczenia będą widoczne jako jedno zdanie.

Jeśli zachodzi potrzeba podzielenia tekstu na osobne akapity, trzeba użyć jakiegoś symbolu zastępczego (ja używam \\), a później skorzystać z funkcji znajdowania i zamiany w Wordzie po wyeksportowaniu pliku docelowego.
Po zakończeniu tłumaczenia ostateczne sczytanie/redakcję warto zrobić w Wordzie (czy innym edytorze tekstu), nie w programie CAT, co ułatwi pracę z większymi blokami tekstu i pomoże zniwelować potencjalne „nieciągłości” wynikające z tłumaczenia zdanie po zdaniu.
- Krzywa uczenia – podstawowe funkcje programu CAT można opanować w parę godzin korzystając z bezpłatnych materiałów szkoleniowych dostępnych online i odrobiny ćwiczeń, ale należy się liczyć z frustracją i stromą krzywą uczenia się, zwłaszcza jeśli to pierwsze zetknięcie z tego typu narzędziami i wymagane jest poznanie nowych pojęć oraz (mniej lub bardziej) wymuszonego przebiegu pracy. Programy oferują różny poziom złożoności i choć generalnie przebieg pracy jest wszędzie taki sam, poszczególne implementacje i wymagane czynności mogą się różnić. Zwracam uwagę, że przy pracy z tekstami literackimi zwykle nie jest wymagana znajomość wszystkich, często bardzo rozbudowanych, funkcji współczesnych programów CAT, ale niektóre ze wspomnianych przeze mnie funkcji (np. wyszukiwanie w internecie) wymagają pogrzebania w ustawieniach i skonfigurowania.
- Koszt – powiedzmy bez ogródek: programy CAT to oprogramowanie profesjonalne i tak też jest wyceniane. Czy wydajność pracy z takimi programami wzrośnie na tyle, żeby uzasadnić wydanie kilkuset euro? Może, z czasem. A może nie. Można jednak zacząć od darmowego oprogramowania, takiego jak OmegaT (open source) czy działający online SmartCAT (radzę uważnie przeczytać umowę licencyjną) albo Wordfast Anywhere, spróbować programów z opłatą miesięczną, jak Memsource, czy zapoznać się z wersjami próbnymi programów czysto komercyjnych jak memoQ (mój ulubiony, z 45-dniową wersją próbną) czy SDL Trados Studio. Warto jednak pamiętać stare powiedzenie – dostajesz to, za co zapłaciłeś. Darmowe narzędzia potrafią być w zupełności wystarczające, ale płacąc za komercyjne oprogramowanie desktopowe można dostać dużo więcej.
Podsumujmy
Czy programy CAT mogą być używane w tłumaczeniach literackich/kreatywnych? Zdecydowanie. Będą pomocne? Tak, na wiele sposobów. Czy dostatecznie, by zainwestować w oprogramowanie komercyjne? Może, to zależy.
Full disclosure: nie sprzedaję programu memoQ ani nie pracuję dla firmy, ale prowadzę komercyjne szkolenia z obsługi tego programu.