
 If you happen to translate text with numbered references, you’ve probably encountered problem with incorrect segmentation when the reference number is placed just after end of sentence period, like this:
If you happen to translate text with numbered references, you’ve probably encountered problem with incorrect segmentation when the reference number is placed just after end of sentence period, like this:
This is an example sentence.² With a second sentence added.
In most cases the above sentences will be imported to CAT tools as a single segment, which will require manual splitting to achieve correct leverage in TM. Fortunately there is a simple solution for this problem.
A frustrated friend recently posted about this problem on Twitter, and when I asked for details of her problem, she sent me a sample file with lots and lots of references, asking if it’s possible to create segmentation rules, which would segment such text correctly. It came out to be quite simple matter, and since the problem may be more widespread, I thought I should make the rule public.
The rule properly segments text in the following cases:
- word.1 Next sentence.
- word.1,2 Next sentence
- word.1-3 Next sentence
- word.”1 Next sentence (for two quotation variants: ” ” )
- word.)1 Next sentence (for “)” and “]” )
Below you’ll find instructions on how to add segmentation rule for memoQ and Trados Studio.
I. memoQ
In memoQ segmentation rules are separate resources. There are always default segmentation rules for a given source language, but you can create your own rules used only in particular project. In the procedure below I’ll describe how to copy default rules for English and how to make it default for new projects in memoQ 2014 R2.
- Open memoQ.
- Click Resource console icon.
- Click Segmentation rules category.
- From the Language drop-down select English (or English variant, or any other source language you need this rule for).
- Click Create new command in the lower part of the window.
- Enter name for the new rule set, e.g. Default with references. New rule set will contain a copy of default settings.
- Select new rule and click Edit.
- Click Advanced view in the lower left corner of the dialog (if you have memoQ older than 2014 R2, simply skip this step).
- In the editing field below Rules pane paste the following regular expression:
\p{Ll}\.[\)\]”"]?\d+([-–,]\d+)?#!#[\s]+\p{Lu} - Click Add.
- Click OK and Close, to close the resource console.

To make the modified rule default for new projects:
- Click Options icon (for older memoQ versions: Tools > Options) to display Options dialog.
- In the Default resources field and Segmentation rules category use Language drop-down to select English (or any other language you’ve edited).
- Check the option field next to newly created segmentation rules (e.g. Default with references).
- Click OK.
New projects will use this segmentation rules for selected source language.
II. Trados Studio
In Studio segmentation rules are stored within translation memories, so you need to edit any TM you wish to add this rule to. (The editing procedure is copied from SDL Knowledge base.)
- Open SDL Trados Studio.
- Go to Translation Memory View.
- Click on File > Open > Open Translation Memory to add the translation memory you wish to change to the list of translation memories.
- Right-click on the listed translation memory and select Settings from the menu; this opens the Translation Memory Settings dialog box.
- Click on Language Resources.
- On the right-hand side highlight Segmentation Rules and press Edit.
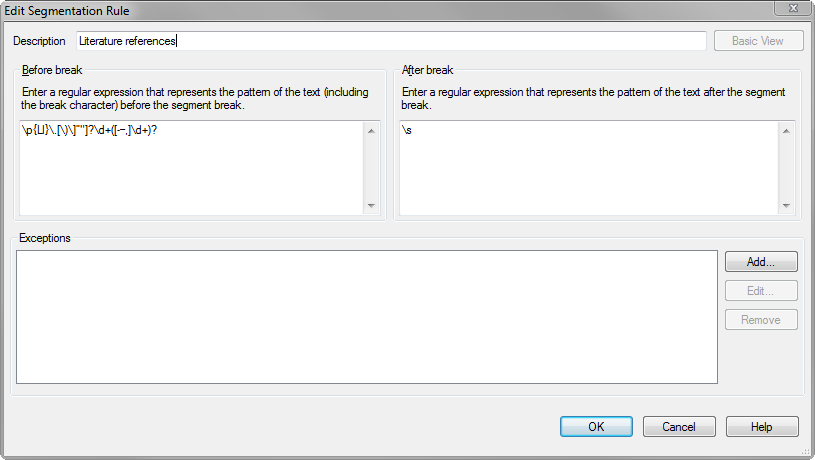
- In the Segmentation Rules dialog box, click Add to open the Add Segmentation Rule dialog box.
- Enter for example Literature references in the Description field.
- Click Advanced View.
- In the field Before break replace the existing regular expression with the following:
\p{Ll}\.[\)\]”"]?\d+([-–,]\d+)? - In the field After break replace the existing regular expression with the following:
\s - Click OK several times to confirm the changes until you are back in the Translation Memory View.
Please note that when I was editing the rule in Studio I’ve encountered a peculiar bug: any file was segmented correctly only on the second try, that is, if you add the rules to your TM and the file will not be segmented correctly, delete the file and import again. It should work on the second try.
If the rules are not enough for you, e.g. you need rules for some special cases, please contact me, I may be able to help.
17 pings
Skip to comment form