

The XML has a bad reputation amongst translators – quite often it’s being perceived as something complicated and terribly difficult to translate. However, armed with the basic knowledge of the XML file structure and modern translation environment tools it’s actually usually very easy to correctly translate XML. This is the first installment of a three-part series of posts I’m going to write about XML. Part one is a very basic introduction to XML – why and what. Part two will cover XML import in memoQ and part three import in Trados Studio.
The posts are an adaptation of the presentation I gave at the Translation Conference in Warsaw, March 2014.
So, what exactly is this XML thing?
XML stands for eXtensive Markup Language, and it is really a metalanguage, that is a language for defining a markup language. XML specifies rules and general syntax for such markup languages, which by themselves are called applications. Generally markup language is a set of codes or tags that surround content and describe what that content is, or in some cases what it should look like when displayed. Therefore in XML applications tags surround the document and tags may have attributes that further qualify the context of the content.
Let’s say we want to catalogue our book collection. To do so, we need to record some information about the books: it’s author, title, publisher, publication year, genre or subject, and maybe a note. How can we do that? Well, the simplest way would be just to write all that data in a text file. For example:

Example of a simple bibliographic note
That’s easy. It’s not difficult for a human to distinguish and correctly assign different types of information. But what about this example?

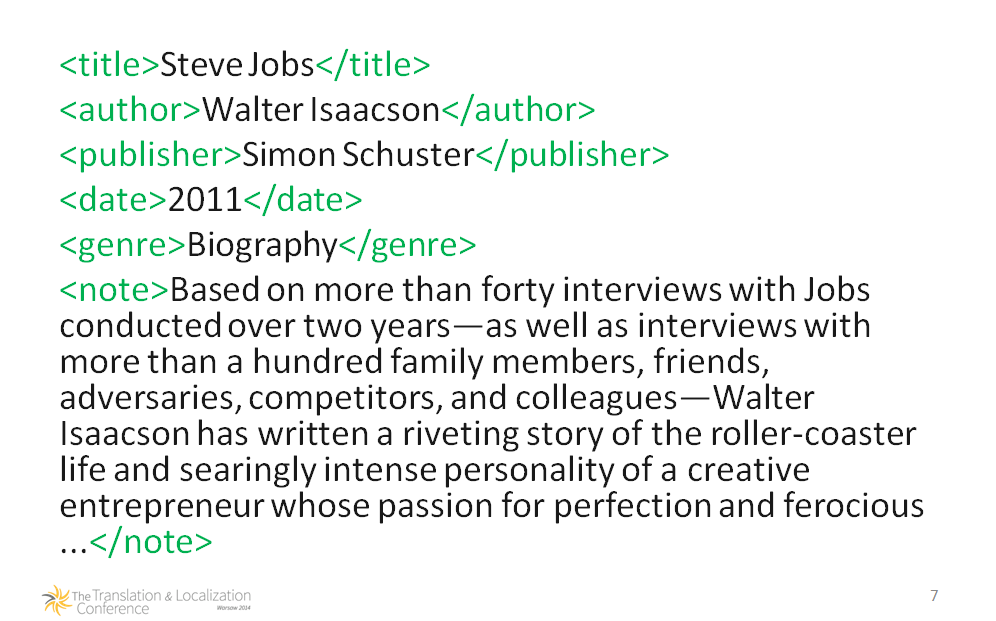
Somewhat less unambiguous bibliographic note
Which of the three first fields contains author, publisher and title? Of course I intentionally picked a name which won’t be hard to recognize, but what about someone less known? As you can see, the correct classification of information may become a challenge. Sure, we can overcome this quite easily:

Bibliographic note with human-readable description
Now it’s easy, right? But how do we know where one kind of information ends and other one begins? A line breaks? If so, then how do we know the note does not ends after the first line? And what if we write both title and author in the same paragraph? Well, that’s where XML tags come in handy. We can use them to explicitly describe the information.
XML tags for bibliographic note
The <something> around the data are tags or elements describing information inside them, so they are basically an information about information. Now the information is unambiguous and clear. What’s more, we can re-arrange the content in any way we like and it won’t matter, because it will still be clear. And we can add certain attributes to our tags:

XML tags with attributes
As you can see in this case I have defined attributes concerning the look of the content. Additionally there are some tags which does not define the type of content, just formatting. The text from such XML file can be transformed using special rules stored in XSLT file (eXtensibe Stylesheet Language Transformations) to generate graphical output like this

Formatted output of an XML file after XSLT transformation
However, proper XML file requires some more data than just these tags.
The first line of an XML document should contain XML declaration, which specifies the XML version and the character encoding used in the document.

Added XML version and encoding declaration
If there is no version declaration, XML version 1.0 is assumed and the default encoding is UTF-8 (8-bit Unicode Transformation Format). In the next line most of the XML files contain DTD declaration (or whole definition) – a Document Type Definition defines the elements, attributes and other markup allowed in the given XML document.

Added DTD declaration
In this case a DTD for this particular file type is referenced. It’s a file I created myself and it is not very complex (although actually contains definition for additional attribute — translate — not used in the examples):

DTD file for the XML file used in examples
Instead of DTD you can see an XSD file referenced in the declaration – XSD stands for XML Schema Definition and is somewhat more advanced than DTD. But you don’t really have to know anything about DTD or XSD other than the fact, that it’s a file containing a description (or definition) of possible tags and attributes in an XML file. So, back to our XML file.
What we really mised here before was the root element – it can be called anything, but the most common is just <root> or <body>. In our case, since we are creating a book catalogue, we can name our root element <collection>.

Fully valid XML file with a single entry
Still, it’s just a single book, while we want to have a whole catalogue, so, I think we need to add some more structure:

Fully valid XML file with two “book” entries
The “collection” is our root element. Book is the level one element, and it’s a parent for elements like title, author or publisher. These elements are children. Each root element can have many child elements, but each child can have only one parent.
Of course this is a very simple example XML file, but it does illustrate the basics — XML file structure, tags and attributes. I also think that it should be obvious to you what do we actually want to translate in this file.
In the next part I’ll describe the process of importing an XML file into memoQ and how to adapt an XML filter to a particular XML file.