
XML ma złą reputację wśród tłumaczy – bardzo często jest postrzegany jako coś skomplikowanego, co niezwykle trudno prawidłowo przetłumaczyć. Jednak dysponując podstawową wiedzą na temat struktury plików XML oraz nowoczesnymi programami do wspomagania tłumaczeń tak naprawdę praca z plikami XML jest dość prosta. Niniejszy tekst jest pierwszym z trzyczęściowej serii na temat tłumaczenia plików XML. Część pierwsza to podstawowe wprowadzenie do formatu XML – takie „co i jak”. W części drugiej omówię import plików XML do programu memoQ, a w części trzeciej do programu Trados Studio.
Wpisy te stanowią adaptację prezentacji, jaką przedstawiłem na konferencji Translation Conference w Warszawie w marcu 2014 r.
Czym tak właściwie jest ten XML? XML to skrót od eXtensive Markup Language – rozszerzalny język znaczników – i tak naprawdę jest metajęzykiem, czyli językiem do definiowania języka znaczników. XML określa reguły i ogólną składnię dla języków znaczników, które z kolei są określane mianem aplikacji. Ogólnie rzecz biorąc język znaczników to zestaw kodów lub znaczników (tags), które otaczają treść i opisują zawartość, a w pewnych przypadkach również to, jak powinna wyglądać. W związku z tym w aplikacjach XML dokument jest otoczony znacznikami, a znaczniki mogą posiadać atrybuty, które w bardziej precyzyjny sposób opisują kontekst treści/zawartości. Przypuśćmy, że chcemy skatalogować kolekcję książek. W tym celu musimy zapisać podstawowe informacje dotyczące książek: autora, tytuł, wydawcę, rok publikacji, gatunek czy też temat i może jaką notkę o książce. Jak do tego podejść? Najprostszym sposobem byłoby zwykłe zapisanie wszystkich informacji w pliku tekstowym. Na przykład:

Przykład prostej notki biograficznej
To proste. Człowiek nie będzie miał żadnych trudności z rozróżnieniem i właściwą klasyfikacją różnych typów informacji. Ale co z tym przykładem?

Trochę bardziej niejednoznaczna notka bibliograficzna
Które z pierwszych trzech pól zawiera informację o autorze, wydawcy i tytuł? Oczywiście wybrałem nazwisko, które będzie łatwo rozpoznać, ale co w sytuacji, gdy napotkamy kogoś mniej znanego? Jak widać, właściwa klasyfikacja informacji może się stać wyzwaniem. Oczywiście możemy sobie z tym dość prosto poradzić:

Notka bibliograficzna z opisem czytelnym dla człowieka
Teraz już łatwiej, prawda? Ale skąd właściwie wiemy, gdzie kończy się jeden rodzaj informacji a zaczyna inny? Końce linii? Jeśli tak, to skąd wiemy, że opis („note”) nie kończy się po pierwszej linii? A jeśli napiszemy tytuł i autora w tym samym akapicie? Tutaj właśnie przydają się znaczniki XML. Możemy ich użyć do jednoznacznego opisania informacji.
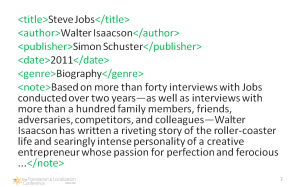
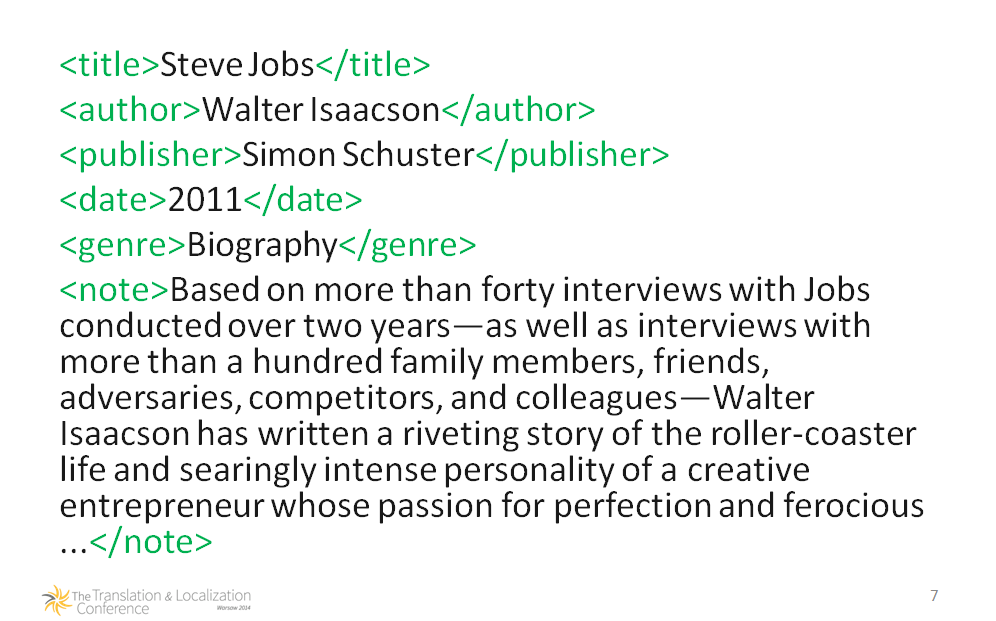
Znaczniki XML w notce bibliograficznej
To <coś> wokół danych to
znaczniki lub
elementy opisujące zawartą wewnątrz informację, czyli informacja o informacji. Teraz informacja wewnątrz znaczników jest jasna i jednoznaczna, zrozumiała także dla systemów komputerowych. Co więcej, możemy dowolnie zmieniać kolejność treści i nie będzie to miało znaczenia, ponieważ wciąż pozostanie jednoznaczna. Możemy także dodać do znaczników pewne atrybuty:

Znaczniki XML z atrybutami
Jak widać, w tym przypadku zdefiniowałem atrybuty definiujące wygląd treści. Dodatkowo mamy tu znaczniki nie definiujące typu treści, tylko jej formatowanie (znaczniki „<i>” oraz „<b>”). Tekst z takiego pliku XML można przetworzyć korzystając ze specjalnych reguł zapisywanych w plikach XSLT (eXtensibe Stylesheet Language Transformations) w celu wygenerowania tekstu sformatowanego, np. o takim wyglądzie:

Sformatowany wynik przekształcenia pliku XML z użyciem reguł XSLT
Jednakże prawidłowy plik XML wymaga wprowadzenia dodatkowych danych. Pierwszy wiersz dokumentu XML powinien zawierać
deklarację XML, określającą wersję XML oraz kodowanie znaków stosowane w dokumencie.

Dodano deklarację wersji i kodowania XML
Jeśli plik nie zawiera deklaracji wersji, domyślnie przyjmowana jest wersja 1.0 oraz kodowanie UTF-8 (8-bit Unicode Transformation Format). W drugim wierszu większość plików XML zawiera deklarację DTD (lub całą definicję) – DTD oznacza Document Type Definition (definicja typu dokumentu) i jest to opis elementów, atrybutów oraz innych elementów dozwolonych w danym typie plików XML.

Dodano deklarację DTD
W tym przypadku plik zawiera odwołanie do DTD specjalnie dla tego typu pliku. To dość prosta deklaracja stworzona przeze mnie (choć zawiera definicję atrybutu nie stosowanego w przykładach, czyli „translate”):
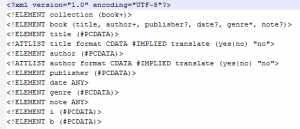
Plik DTD opisujący elementy formatu XML stosowanego w przykładach
Zamiast DTD często stosowane jest odwołanie do pliku XSD (XML Schema Definition), który stanowi nieco bardziej zaawansowany rodzaj deklaracji dopuszczalnych treści. Tak naprawdę jednak jedyne, co trzeba wiedzieć o DTD lub XSD to fakt, że jest to plik zawierający opis (lub definicję) możliwych znaczników i atrybutów pliku XML. Wróćmy więc do naszego pliku XML. Tak naprawdę brakuje w nim elementu głównego (
root) – może mieć dowolną nazwę, jednak najczęściej jest to po prostu <root> lub <body>. W naszym przypadku, ponieważ tworzymy katalog książek, możemy sobie nazwać element główny <collection>.

Poprawny plik XML z jednym wpisem
Mimo wszystko nasz plik wciąż zawiera fiszkę tylko jednej książki, a skoro chcemy stworzyć cały katalog, powinniśmy dodać trochę głębszą strukturę:

Poprawny plik XML z dwoma wpisami „book”
Elementem głównym (root) jest element „collection”. „Book” to element poziomu pierwszego, będący elementem nadrzędnym (parent) elementów takich jak „title”, „author” i „publisher”. To elementy podrzędne (children). Każdy element nadrzędny może mieć dowolną liczbę elementów podrzędnych, ale dany element podrzędny może mieć tylko jeden element nadrzędny. Oczywiście mamy tu do czynienia z bardzo prostym plikiem XML, jednak wystarczy on, do zilustrowania podstaw – struktury pliku XML, znaczników i atrybutów. Sądzę też, że dość oczywiste jest, co powinniśmy przetłumaczyć w tym pliku. W następnej odsłonie opiszę proces importowania pliku XML do programu memoQ oraz sposób dostosowania filtra XML do danego typu pliku XML.











3 pings