
 memoQ is an excellent CAT/TEnT tool which offers plenty of advanced productivity features out of the box, but with little tinkering can be made even more useful. One of the advanced memoQ features is Auto-translatables: using regular expressions you can define how certain source text should be modified in target language. The rules can be quite advanced, e.g. for date format conversion from English “Monday, January 3rd, 2106” to Polish “Poniedziałek, 3 stycznia 2016 r.”. One of the most frequent uses for auto-translatables is the conversion of numeric strings according to target language rules. It used to be the most basic auto-translatable application – it’s not needed so much now, since memoQ offers automatic, out-of-box number format conversion: if your source segment contains numbers formatted according to source language rules, just press Ctrl and from the displayed list select value formatted according to target language rules. The thing is, source format not always follows the rules (defined in Microsoft libraries used by memoQ).
memoQ is an excellent CAT/TEnT tool which offers plenty of advanced productivity features out of the box, but with little tinkering can be made even more useful. One of the advanced memoQ features is Auto-translatables: using regular expressions you can define how certain source text should be modified in target language. The rules can be quite advanced, e.g. for date format conversion from English “Monday, January 3rd, 2106” to Polish “Poniedziałek, 3 stycznia 2016 r.”. One of the most frequent uses for auto-translatables is the conversion of numeric strings according to target language rules. It used to be the most basic auto-translatable application – it’s not needed so much now, since memoQ offers automatic, out-of-box number format conversion: if your source segment contains numbers formatted according to source language rules, just press Ctrl and from the displayed list select value formatted according to target language rules. The thing is, source format not always follows the rules (defined in Microsoft libraries used by memoQ).
Sometimes it’s still more convenient to use auto-translatables for format conversion. memoQ comes with some rules defined for the following target languages: English, French, German, Hungarian and Swiss, so in theory with some basic regular expressions (regexp for short) knowledge you should be able to modify them if they don’t work exactly as needed. Unfortunately, the rules shipped with memoQ have two drawbacks:
- they are “one size fits all” with regard to source number format, so some trade-offs were necessary. And there are specific cases where they fail,
- they are quite messy, not easy to interpret and modify.
Since the subject of auto-translatable rules for numbers is regularly raised on memoQ mailing list, I decided to share the simple, but rather robust rules created for for English to Polish format conversion that are easy do customize according to any source/target language combination. There is also a second, more complex set of En-Pl rules that I actually use in my daily work.
If you want to modify the rules, I strongly suggest to edit them using a text editor before importing into memoQ. Unfortunately the built-in memoQ editor for auto-translation rules is not very convenient, because due to its fixed size, you can see only small part of longer expressions, plus rules are re-ordered every time you change one of them. I suggest using Notepad++ for editing, but any text editor will do. If you do use Notepad++, after opening the file click Language menu and select XML – this will make editing much easier, because editor will show elements with different colors (see screenshot below). The rules are numbered, but you won’t see the numbers (or comments) once you import the file into memoQ.
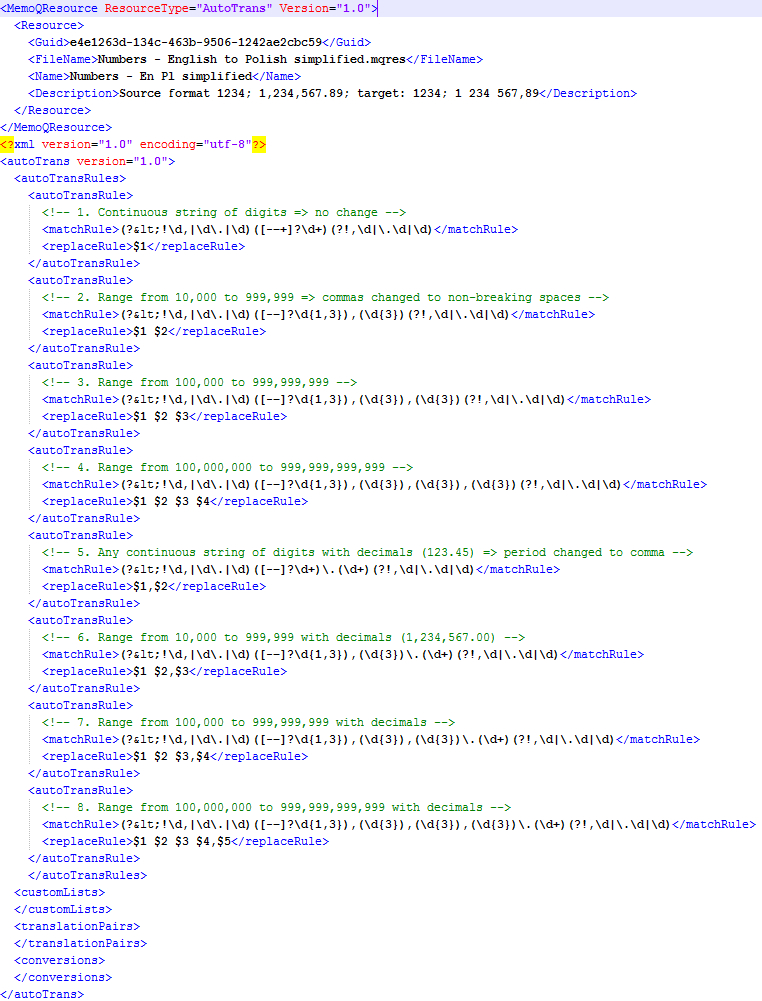
Auto-translatable rules for numbers format conversion opened as .mqres file in Notepad++ with XML syntax clolring
First some background information:
The file is designed to convert English numbers into Polish formats – that means comma (,) as thousands separator and period (.) as decimal separator for source and (non-breaking)space ( ) as thousands separator and comma (,) as decimal separator for target. Several examples:
|
English |
Polish |
|
123 |
123 |
|
12,345 |
12 345 |
|
123.45 |
123,45 |
| 12,345.67 |
12 345,67 |
English financial documents sometimes use space instead of comma for thousands separator. The rules won’t work in such case, they would require modification (see near the end of post). To explain how this work, I’ll describe the rule number 2 (screenshot above).
<matchRule>(?<!\d,|\d\.|\d)([-–]?\d{1,3}),(\d{3})(?!,\d|\.\d|\d)</matchRule>
<replaceRule>$1 $2</replaceRule>
Match rule:
- (?<!\d,|\d\.|\d) – this part says: do not match, if before the numbers there is a digit (\d) followed by comma (,) or (I) number followed by period (\.) or number. The “<” is actually way of encoding “<”, and that’s what you will see once you import the rules into memoQ.
- ([-–]?\d{1,3}),(\d{3}) – this part says: match if one, two or three digits (\d{1,3}, first numbered group), comma (,), and exactly three digits (\d{3}, second numbered group). Optionally there can be a dash or minus sign at the beginning ([-–]?), if present, it will be part of the first group.
- (?!,\d|\.\d|\d) – this part says: do not match, if after the point 2. there is a comma and digit (,\d) or period and digit (\.\d) or digit (\d).
This will match: 1,234 or 12,345 or 123,456
Replace rule:
- $1 $2 – this means get the write of the first group (point 2. above), then non-breaking space, then content of the second group (point. 2 above).
The conversion result: 1 234 or 12 345 or 123 456
As you can see, the actual number matching is done by rule in point 2, so what are points 1 and 3 for (blue text)? They are called “assertions” and they are there to limit matching to only the group you want. Let’s examine what would happen, if we’d write two following rules to match thousands in two ranges:
([-–]?\d{1,3}),(\d{3}) for numbers xxx,xxx
([-–]?\d{1,3}),(\d{3}),(\d{3}) for numbers xxx,xxx,xxx
Let’s use them on actual segment with numbers:
![]()
As you can see, the second rule matches as it should, but the first one matches too, because the rule matches also to a part of longer number. And that’s why I have used the assertions – to limit matching. And to exclude matching of longer numbers, one must exclude combination of the symbols appearing in the numbers formatting with numbers. That’s why in the “before” part I have excluded “\d,” (digit followed by comma), “\d\.” (digit followed by period) and “\d” (just number), and in the “after” part the same in reverse order: “,\d” (comma followed by digit), “\.\d” (period followed by digit) and “\d” (just digit).
So the important thing to remember is that if you want to modify the rules to different system, you need to replace current thousands separator and decimal symbol in both matching and assertions parts.
Before we proceed to actual modifications, one more important explanation:
Source (matchRule) and target (replaceRule) are interpreted differently when it comes to symbols. In regular expressions period (.) has a special meaning (“any character”), so if we want to match exactly period, we need to use (\.). However on the replacement side everything except “$number” is treated literally, so if you want to use period, just write a period. Similarly, while “\s” means “space” in the matching part, to get a space on the replacement side just type a space. Or paste non-breaking space from any program (e.g. Word or memoQ translation editor).
Now I will show you how to modify the rules for different source/target combination using Swiss as the source language format: apostrophe (’) as thousands separator, period (.) as decimal separator and Norwegian as target format: period (.) as thousands separator, comma (,) as decimal separator. Examples:
|
Swiss |
Norwegian |
|
123 |
123 |
|
1’234 |
1.234 |
|
12’345 |
12.345 |
|
123.45 |
123,45 |
|
12’345.67 |
12.345,67 |
Of course start by downloading the file, then open it in text editor.
Let’s try to modify rule number 2:
<matchRule>(?<!\d,|\d\.|\d)([-–]?\d{1,3}),(\d{3})(?!,\d|\.\d|\d)</matchRule>
<replaceRule>$1 $2</replaceRule>
We need to replace comma (,) with apostrophe (’) in the source part:
<matchRule>(?<!\d’|\d\.|\d)([-–]?\d{1,3})’(\d{3})(?!’\d|\.\d|\d)</matchRule>
And replace space with period in the target part:
<replaceRule>$1.$2</replaceRule>
That’s it. I have replaced comma with an apostrophe, but I didn’t touch the period, because it’s also used in this source system, just in a different role. To cover everything, let’s try the rule number 6, with both number grouping symbol and decimal separator:
<matchRule>(?<!\d,|\d\.|\d)([-–]?\d{1,3}),(\d{3})\.(\d+)(?!,\d|\.\d|\d)</matchRule>
<replaceRule>$1 $2,$3</replaceRule>
We need to change it to:
<matchRule>(?<!\d’|\d\.|\d)([-–]?\d{1,3})’(\d{3})\.(\d+)(?!’\d|\.\d|\d)</matchRule>
<replaceRule>$1,$2.$3</replaceRule>
This kind of changes needs to be done for every rule in the document, both for source (matchRule) and target (replaceRule). I advise not to use “Find and replace” for rules editing (especially not “replace all”), because it’s easy to mess up something by mistake.
And since there are two types of apostrophes (straight and curly: ‘ and ’), to make the rules more foolproof you may want to create two sets of auto-translatables – one for each kind and use both in your projects (if you prefer to keep regexes simple). Or you may try to use one set of rules making it a bit more complex:
<matchRule>(?<!\d’|\d'|\d\.|\d)([-–]?\d{1,3})(?:’|')(\d{3})\.(\d+)(?!'\d|’\d|\.\d|\d)</matchRule>
Now there are separate conditions in assertions and alternative matching condition for separator: (?:’|’ ). The use of “?:” makes this group non-numbered, so this not affects target groups.
And one last example for space as thousands separator instead of comma:
<matchRule>(?<!\d\s|\d\.|\d)([-–]?\d{1,3})\s(\d{3})(?!\s\d|\.\d|\d)</matchRule>
Once you finish your edits, save the file (it has to be plain text with .mqres extension and UTF-8 encoding and simply import to memoQ (Resource console > Auto-translatables > Import). If memoQ complains:
- during import – it means that XML structure is broken. Make sure all the <> parts are intact and that for every opening tag (<whatever>) there is exactly one closing tag of the same type (</whatever>),
- when adding rules to project – it means there is some error in the regular expressions part. When you click “More” button on the error notification dialog memoQ will show first offending line. Make sure all brackets, parentheses and curly brackets are paired and the syntax is correct.
I also encourage you to check the auto-translatable set I use for numbers conversion – there are additional rules for matching telephone numbers (rules 11 and 12), proper recognition and conversion of percentage values (15, 16) and temperatures (°C and °F, 13 and 14). Plus rules for special case of numbers between 1,000 and 9,999, where thousands separator is not used in Polish (so 1000 and 9999 respectively).
* * *
An additional note regarding ease of rules editing. memoQ offers excellent mechanism of #lists# and in theory it should be easy to create rule set where all you have to do to modify rules according to your source rules would be to change content of #thousands_separator# and #decimal_place# lists. I tried, that was my original idea behind this post. Unfortunately it’s not possible, because you can’t use lists in assertions (well, you can, but the results are not what one would expect).
4 pings