



Programy wspomagające tłumaczenia (CAT)
Ponieważ na różnych grupach poświęconych tłumaczeniom dość często pojawiają się pytania o programy typu CAT (Computer Aided Translation), a trudno znaleźć tekst, który w przystępny sposób omawiałby ich działanie, podjąłem próbę krótkiego omówienia tematu.
Każdy, kto zajmuje się tłumaczeniem dowolnych tekstów nie-literackich zauważył, że zdarzają się sytuacje, gdy pewne fragmenty tekstu się powtarzają - czasami są to całe zdania, czasem pewne frazy. Bywa, że nowe zdanie różni się od już przetłumaczonego ledwie jednym-dwoma słowami. W takiej sytuacji naturalne wydaje się skopiowanie wcześniej przetłumaczonego tekstu z poprawką we właściwym miejscu, zamiast przepisywania całego zdania, tłumacząc je od nowa. Na tym właśnie polega zasada działania programów CAT - programy te po prostu podpowiadają wcześniejsze tłumaczenie, jeśli dany kawałek tekstu jest podobny do czegoś, co już tłumaczyliśmy.
Na wstępie wypada podzielić programy wspomagające tłumaczenie na dwie kategorie, z kryterium czysto funkcjonalnym - otóż mamy nakładki na edytor tekstu (Rys. 1) - chyba wyłącznie do MS Word - oraz programy z własnym edytorem (Rys. 2, 3). Te drugie oferują większą elastyczność i wygodę, umożliwiając tłumaczenie szerokiej gamy formatów plików (mn. HTML, XML, edytory tekstu, pliki programów do składu DTP) ale jeśli ktoś przyzwyczaił się do pisania w Wordzie, zapewne będzie wolał korzystać ze znanego sobie środowiska.
Jak praktycznie wygląda praca z narzędziem CAT? Plik dzielony jest na tzw. segmenty. Podział ten jest dość naturalny, ponieważ segmentami najczęściej są zdania bądź ich fragmenty, jeśli w zdaniu występują dwukropki czy średniki - zresztą w większości programów CAT sposób segmentacji dokumentu, czyli podziału na segmenty można definiować, na przykład aby uniknąć podziału zdania po "np.". Niezależnie od tego, czy pracujemy w Wordzie, czy w specjalistycznym edytorze, program "wczytuje" pierwszy segment. W Wordzie jest on wyróżniany graficznie, w edytorze wyświetlany w specjalnym oknie. U góry mamy segment w języku źródłowym, poniżej możliwość wpisania tłumaczenia (w języku docelowym). Jeśli dopiero zaczęliśmy pracę nad tłumaczeniem mając pustą "pamięć", oczywiście program w niczym nam tu nie pomoże, trzeba samemu wpisać tekst. Po zatwierdzeniu wpisanego tłumaczenia (zazwyczaj za pomocą kombinacji klawiszowej, np. Alt-+ [Trados]), program automatycznie przechodzi do następnego segmentu (zdania). Jeśli jednak w którymś kolejnym segmencie trafimy na tekst podobny do już przetłumaczonego, to oprócz tekstu źródłowego program CAT wyświetli nam również tekst wcześniejszego tłumaczenia, wraz z informacjami dodatkowymi. Oznaczenie kolorystyczne pozwoli już na pierwszy rzut oka stwierdzić, czy segment jest identyczny z już tłumaczonym (zgodność 100%, Rys. 2), czy podobny w mniejszym stopniu (zgodność <100%, Rys. 3). Oczywiście dostaniemy dokładną procentową wartość zgodności, a co najważniejsze, program podświetli różnice między segmentami. W ten sposób na pierwszy rzut oka widać, którymi słowami różnią się tłumaczone segmenty. Dodatkowe informacje obejmują zazwyczaj identyfikator autora tłumaczenia (o tym za chwilę), datę jego powstania itp.
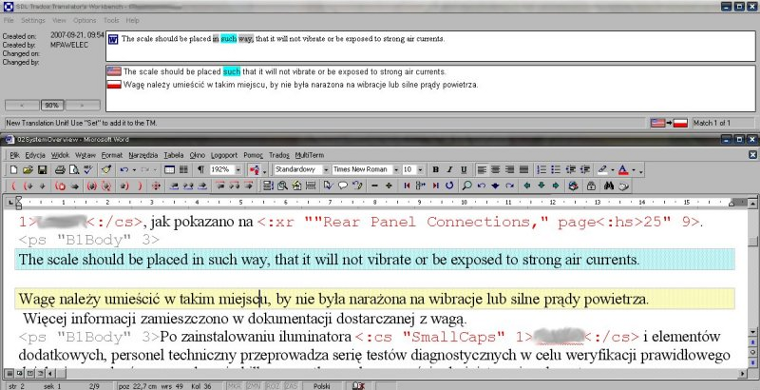
Rys. 1. Program Trados Translator´s Workbench - właściwy program CAT (u góry), we współpracy z edytorem MS Word. Na żółto oznaczono bieżący segment tłumaczenia, powyżej segment źródłowy. W oknie programu Workbench widać różnice w stosunku do wcześniej przetłumaczonego, podobnego segmentu.
W miarę pracy program CAT tworzy coraz większą bazę tłumaczeń, czyli tak zwaną pamięć tłumaczenia (Translation Memory, TM). Im większa pamięć, tym lepiej dla nas, bo większa szansa, że znajdzie się tam coś podobnego do tekstu nad którym właśnie pracujemy. Jednak należy pamiętać o pewnym ograniczeniu: nie jest dobrym pomysłem używanie jednej pamięci do wszystkich tłumaczeń - takie "szwarc, mydło i powidło". Pamięć powstała na bazie tłumaczeń instrukcji serwisowych do samochodów nie przyda się zupełnie przy tłumaczeniach umów handlowych a TM medyczna będzie bezużyteczna przy lokalizacji oprogramowania. Co więcej, TM powstała przy tłumaczeniu instrukcji elektrokardiografu może być prawie bezużyteczna przy sprzęcie do RTG. Piszę "prawie", bo i tu można skorzystać z takiej pamięci - instrukcje do aparatury medycznej zawsze zawierają część ze specyfikacją, w której pewne formułki powtarzają się praktycznie bez zmian - jeśli raz coś takiego przetłumaczymy, za drugim razem wystarczy podstawić inną nazwę urządzenia.
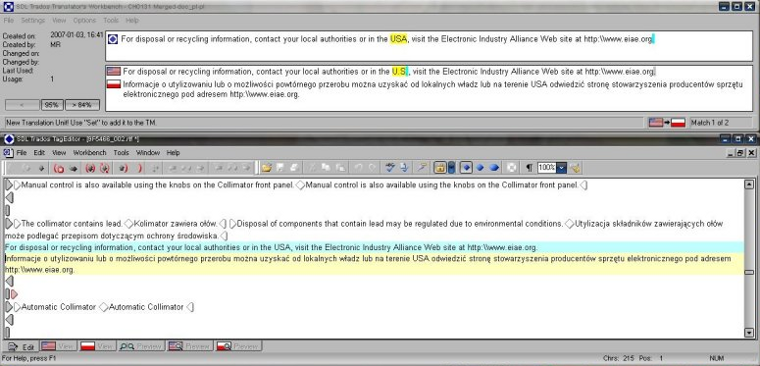
Rys. 2. Trados Translator´s Workbench współpracujący z edytorem TagEditor, elementem pakietu Trados. Podobnie jak na poprzedniej ilustracji, widać różnice między segmentem w pamięci, a bieżącym. Formatowanie tekstu zapewniają znaczniki (tagi), na ilustracji widoczne w formie zminimalizowanej, jako szare "trójkąty".
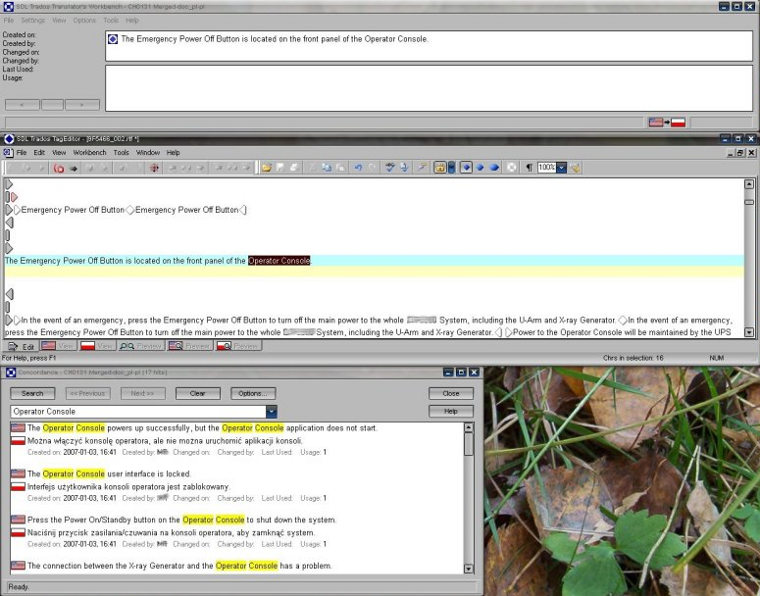
Rys. 3. Przykład wykorzystania funkcji Concordance - wyszukiwanie w TM wcześniejszego tłumaczenia zadanej frazy.
Pamięci tłumaczeniowe oferują przy tym świetny sposób oszczędzania czasu, zwiększania produktywności i konkurencyjności.
Przypuśćmy, że dysponujemy TM z tłumaczenia wykonanego dla określonego klienta, niech to będzie firma A, dla której tłumaczyliśmy instrukcję bulbulatora A200. Klient zgłasza się do nas o przetłumaczenie instrukcji nowej wersji urządzenia, A300, wzbogaconego o nowe funkcje. Dzięki posiadaniu TM jesteśmy w stanie w ciągu kilkunastu sekund policzyć całkowitą objętość tekstu, oraz ilość nowych słów - segmentów, które różnią się od tekstu już przetłumaczonego. Może się okazać, że w instrukcji o objętości 50 tys. słów tekstu całkiem nowego jest raptem np. 3 tys. słów, plus kilka tysięcy słów częściowo zmienionych (oczywiście w przypadku nowych i zmienionych słów tak naprawdę liczone są nowe segmenty). Jasne jest, że takie tłumaczenie zabierze znacznie mniej czasu niż tekst całkiem nowy, można też zaoferować klientowi rabat, lub - jeśli ten zna systemy CAT - policzyć tylko za nowe tłumaczenie (czego zresztą, moim zdaniem, wymaga uczciwość). Co więcej, duże firmy międzynarodowe same korzystają z narzędzi CAT do przygotowywania plików do tłumaczeń i przechowują własne pamięci TM - dzięki temu tłumacz, po otrzymaniu takiego pliku, może z łatwością zachować terminologię i stylistykę wcześniejszych tłumaczeń, na dodatek dzięki identyfikatorowi widzi, kto wcześniej pracował z TM.
Można długo wyliczać dalsze zalety pracy z programami CAT, ale podam tylko trzy.
- Po pierwsze - możliwość bardzo łatwego przeszukiwania TM - jeśli jakiś termin był już przetłumaczony, za pomocą dwóch kliknięć czy też kombinacji klawiszowych możemy wyświetlić wszystkie segmenty, w których występował, wraz z tłumaczeniem - to funkcja "Concordance", której zastosowanie widać na Rys. 3.
- Po drugie - możliwość definiowania tzw. "placeables", czyli fragmentów tekstu, które program rozpoznaje i umożliwia skopiowanie za pomocą skrótu klawiszowego z segmentu źródłowego do tłumaczenia - może to być np. data (wraz z automatyczną konwersją na inny format), nazwa produktu czy wartość liczbowa.
- Po trzecie - chyba wszystkie programy CAT dysponują własnymi, lub umożliwiają współpracę z modułami zarządzania terminologią - swoistymi słownikami, podpowiadającymi właściwe tłumaczenia zdefiniowanych terminów.
Podsumowując - programy CAT są doskonałym rozwiązaniem w sytuacji tłumaczenia tekstu elektronicznego o umiarkowanym lub dużym stopniu powtarzalności (np. dokumenty rejestracyjne samochodu, odpis aktu urodzenia, instrukcje tego samego typu urządzenia, licencje lub umowy handlowe), lub w przypadku tłumaczeń o zbliżonej tematyce dla jednego klienta. Nie pomogą natomiast w tłumaczeniach o dużym stopniu zróżnicowania tematycznego lub dla różnych zleceniodawców, wymagających stosowania odmiennej stylistyki i/lub terminologii.
Najważniejsze programy CAT
Pakiet Trados - jego podstawa to Translator´s Workbench, program zarządzający TM. W skład pakietu wchodzi ponadto uniwersalny edytor TagEditor, zestaw makr do pracy w edytorze MS Word, programy wspomagające tłumaczenie plików w formacie Excel i PowerPoint, program WinAlign do tworzenia plików TM z wcześniejszych tłumaczeń, narzędzia umożliwiające tłumaczenie plików programów do składu (InDesign itp.) oraz program MultiTerm, do zarządzania terminologią.
SDLX - obecnie element pakietu Trados, program pracujący z użyciem własnego edytora.
Wordfast - program współpracujący z edytorem MS Word, kompatybilny z plikami w formacie Trados. Jego niewątpliwą zaletą jest stosunkowo niska cena.
Heartsome XLIFF Translation Editor - bardzo dobre narzędzie z własnym edytorem, przystosowane do pracy ze zdalną pamięcią TM (na serwerze biura tłumaczeń lub klienta).
OmegaT - jedyne chyba całkowicie bezpłatne narzędzie CAT, na dodatek dostępne na wszystkie systemy operacyjne (program w języku Java). Najnowsza wersja podobno również potrafi wczytać TM w formacie Tradosa.